I decided a couple days ago to try out Volatility's ability to examine Linux memory images. I had never tried capturing RAM from a Linux machine, aside from .vmem files, so this was all new territory for me. My friend Gleeda recommended I use LiME to capture ram, so I headed over to the LiME Googlecode project page and grabbed a copy. I may post about the entire process later, but just wanted to make a small announcement for now.
After successfully imaging and examining RAM, I decided to make several profiles for machines I regularly interact with. After that, I decided I may as well share them with others. Therefore, I have created a Github page with the four profiles I've created so far. I will be creating and posting more very soon. It isn't much, but I've wanted to find some way to contribute back to the community and thought this would be a good start
Tuesday, December 3, 2013
Saturday, November 30, 2013
Windows Registry Master Class from The Hacker Academy
The Hacker Academy recently released its new Windows Registry Master Class. Prior to its release, Hacker Academy senior instructor Andrew Case contacted me and asked if I'd like to review the course. I, of course, said yes and got signed up when the course was ready. In the interest of full disclosure, I was given free access to the class in exchange for providing feedback on the course content and for review purposes.
The course was written by Andrew Case, Vico Marziale and Joe Sylve. All three are well known in the forensics field and have contributed much. Andrew is one of the core developers of Volatility, as well as a co-developer of RegDecoder with Vico and Joe. Vico is also a co-developer of Scalpel. Joe is also the developer of LiME. These guys know their stuff.
The course is a combination of video lectures along with hands on labs and quizzes. There are 14 course modules, though some of them are broken down into multiple parts, for a total of 21 lecture videos. The course slides from the videos are also provided in PDF format. Other supplemental reading materials are also provided in PDF format. Some of the supplemental reading is necessary to complete the labs and quizzes, while others are simply to help you understand a topic better but not required.
The majority of modules include a hands-on lab and a quiz. The lab is used to answer the quiz questions. I'll describe the lab setup in a moment. Each lab is accompanied by a guide that walks you through how to complete the exercise in case you get stuck. These PDF format lab guides not only help when you get stuck, but they make great reference material for those times later on when you can't quite remember how to solve a particular problem.
The labs themselves are all performed in online virtual machines accessed through your web browser. One is a Windows 7 virtual machine, while the other VM is Ubuntu 12.04 LTS. All the required tools and lab files are pre-loaded on these VM's and ready for use. I really enjoyed working with the labs and felt they added a great deal to the course. I'll provide some examples later in this review. Here are a couple screenshots from the lab VM's.


Module 1 is an introduction to the course and the Windows Registry. The goals of the class and other material are covered, followed by a description of just what the Registry is and why we should care about it. I suspect most people taking the course will have some idea of what the Registry is, but I think there will be many who have no idea just how much they can actually gain from it.
The core hives are all briefly covered, followed by coverage of the NTUSER and UsrClass hives. Finally, methods of acquiring registry hives from running and "dead" machines are covered. There is no lab with this module, per se, but complete instructions for accessing and using the labs is covered in the written material.
Module 2 is when we start diving in to the nuts and bolts of the Registry. Hive structure is covered first, followed by discussion of the various parts of the hives, including keys and values. Records and their headers are also described in detail and help those new to the material to understand how the Registry is put together, so to speak.
Module 3 is the first one to be broken down into multiple lectures. 3a covers the Software hive, 3b covers the System hive and 3c teaches about NTUSER. The purpose of each of these hives is described and many keys of interest are given. It is acknowledged that no one course could cover every possible key that might be valuable to an investigation, but many of the most frequently valuable keys are given. In this module, as well as most all of the others, real world "war stories" are given to help drive the point of the lesson home. 3d covers the "other" Registry hives, being the UsrClass, SAM and Security hives.
Next up, Module 4 talks about recovering Registry data from various Windows backup facilities. Registry data from Windows XP Restore Points, Vista/Win7 Volume Shadow Service and Windows 8 VSS and File History are covered. Using historical Registry data from backups is talked about, such as incorporating them into timelines.
Registry analysis tools is covered in 5a, b and c. 5a talks about several tools, including Access Data's Registry Viewer, RegLookup, MiTeC Windows Registry Recovery and libregf. As with the other modules, there is a lab that gives you the opportunity to try out some of the tools.
5b and 5c cover the "big dogs" in Registry analysis tools: RegRipper and RegDecoder. The use of each is covered in detail, along with other RegRipper related tools, RipXP and Auto_Rip.
I have taken a few halfhearted stabs at learning Perl and Python in the past, but never really got anywhere. I always thought it would be nice to come up with my own RegRipper plugin, but hadn't ever tried. Modules 6a and 6b teach about scripting RegRipper and RegDecoder. After completing 6a, I finally did my first RegRipper plugin. It even worked! ;-)
Deleted Registry hives and keys was next in the course. What happens when keys and values are deleted and information about recovering deleted data is the focus here. Very interesting stuff and something I think could be very useful to many analysts.
While I'm no expert, I greatly enjoy learning about memory forensics. I was pleased to see Module 8 covered the Registry as it appears in RAM. Volatile hives and data are covered here, along with using the great Volatility Framework to access Registry data in a RAM image are all part of this excellent module.
Modules 9 and 10 cover Registry timelines and baselines respectively. Methods of using RegRipper and RegDecoder to create timelines from the registry are explained.
Module 11 is about one of my favorite subjects, malware. This module is all about how malware uses the registry for persistence, as well as the ways it may alter registry settings (such as turning off the firewall, etc.) to allow certain behavior. Also discussed is the way to find evidence of program execution in the Registry to help track down malware.
Anti-forensics is the focus of Module 12. I'm getting ready to go testify in a case next week in which ccleaner was used to attempt to foil forensics data recovery, so I found particular interest in this module. The module covers the various means of anti-forensics and their effects on the Registry very well.
Module 13 is the "final test" so to speak. A scenario is presented and you must use the skills and tools you've learned over the preceding modules to answer the quiz. The instructors did a really nice job putting this together and I think you'll find it was done very well. Finally, Module 14 is simply the end of class wrap-up.
You can probably guess from all that precedes this paragraph, but yes, I do highly recommend this course. At $399, you definitely get your money's worth. The lecture videos are all very good, getting the point across with easy to understand lessons. The labs are also very good. I thought they were both educational and actually kinda fun to work in. I believe the course has something to offer both new analysts and veteran's alike. I've been doing forensic work for about 5 years now and make use of the Registry in most of my investigations. Still, I learned a great deal in this course and think most others will too.
The course was written by Andrew Case, Vico Marziale and Joe Sylve. All three are well known in the forensics field and have contributed much. Andrew is one of the core developers of Volatility, as well as a co-developer of RegDecoder with Vico and Joe. Vico is also a co-developer of Scalpel. Joe is also the developer of LiME. These guys know their stuff.
The course is a combination of video lectures along with hands on labs and quizzes. There are 14 course modules, though some of them are broken down into multiple parts, for a total of 21 lecture videos. The course slides from the videos are also provided in PDF format. Other supplemental reading materials are also provided in PDF format. Some of the supplemental reading is necessary to complete the labs and quizzes, while others are simply to help you understand a topic better but not required.
The majority of modules include a hands-on lab and a quiz. The lab is used to answer the quiz questions. I'll describe the lab setup in a moment. Each lab is accompanied by a guide that walks you through how to complete the exercise in case you get stuck. These PDF format lab guides not only help when you get stuck, but they make great reference material for those times later on when you can't quite remember how to solve a particular problem.
The labs themselves are all performed in online virtual machines accessed through your web browser. One is a Windows 7 virtual machine, while the other VM is Ubuntu 12.04 LTS. All the required tools and lab files are pre-loaded on these VM's and ready for use. I really enjoyed working with the labs and felt they added a great deal to the course. I'll provide some examples later in this review. Here are a couple screenshots from the lab VM's.


Module 1 is an introduction to the course and the Windows Registry. The goals of the class and other material are covered, followed by a description of just what the Registry is and why we should care about it. I suspect most people taking the course will have some idea of what the Registry is, but I think there will be many who have no idea just how much they can actually gain from it.
The core hives are all briefly covered, followed by coverage of the NTUSER and UsrClass hives. Finally, methods of acquiring registry hives from running and "dead" machines are covered. There is no lab with this module, per se, but complete instructions for accessing and using the labs is covered in the written material.
Module 2 is when we start diving in to the nuts and bolts of the Registry. Hive structure is covered first, followed by discussion of the various parts of the hives, including keys and values. Records and their headers are also described in detail and help those new to the material to understand how the Registry is put together, so to speak.
Module 3 is the first one to be broken down into multiple lectures. 3a covers the Software hive, 3b covers the System hive and 3c teaches about NTUSER. The purpose of each of these hives is described and many keys of interest are given. It is acknowledged that no one course could cover every possible key that might be valuable to an investigation, but many of the most frequently valuable keys are given. In this module, as well as most all of the others, real world "war stories" are given to help drive the point of the lesson home. 3d covers the "other" Registry hives, being the UsrClass, SAM and Security hives.
Next up, Module 4 talks about recovering Registry data from various Windows backup facilities. Registry data from Windows XP Restore Points, Vista/Win7 Volume Shadow Service and Windows 8 VSS and File History are covered. Using historical Registry data from backups is talked about, such as incorporating them into timelines.
Registry analysis tools is covered in 5a, b and c. 5a talks about several tools, including Access Data's Registry Viewer, RegLookup, MiTeC Windows Registry Recovery and libregf. As with the other modules, there is a lab that gives you the opportunity to try out some of the tools.
5b and 5c cover the "big dogs" in Registry analysis tools: RegRipper and RegDecoder. The use of each is covered in detail, along with other RegRipper related tools, RipXP and Auto_Rip.
I have taken a few halfhearted stabs at learning Perl and Python in the past, but never really got anywhere. I always thought it would be nice to come up with my own RegRipper plugin, but hadn't ever tried. Modules 6a and 6b teach about scripting RegRipper and RegDecoder. After completing 6a, I finally did my first RegRipper plugin. It even worked! ;-)
Deleted Registry hives and keys was next in the course. What happens when keys and values are deleted and information about recovering deleted data is the focus here. Very interesting stuff and something I think could be very useful to many analysts.
While I'm no expert, I greatly enjoy learning about memory forensics. I was pleased to see Module 8 covered the Registry as it appears in RAM. Volatile hives and data are covered here, along with using the great Volatility Framework to access Registry data in a RAM image are all part of this excellent module.
Modules 9 and 10 cover Registry timelines and baselines respectively. Methods of using RegRipper and RegDecoder to create timelines from the registry are explained.
Module 11 is about one of my favorite subjects, malware. This module is all about how malware uses the registry for persistence, as well as the ways it may alter registry settings (such as turning off the firewall, etc.) to allow certain behavior. Also discussed is the way to find evidence of program execution in the Registry to help track down malware.
Anti-forensics is the focus of Module 12. I'm getting ready to go testify in a case next week in which ccleaner was used to attempt to foil forensics data recovery, so I found particular interest in this module. The module covers the various means of anti-forensics and their effects on the Registry very well.
Module 13 is the "final test" so to speak. A scenario is presented and you must use the skills and tools you've learned over the preceding modules to answer the quiz. The instructors did a really nice job putting this together and I think you'll find it was done very well. Finally, Module 14 is simply the end of class wrap-up.
You can probably guess from all that precedes this paragraph, but yes, I do highly recommend this course. At $399, you definitely get your money's worth. The lecture videos are all very good, getting the point across with easy to understand lessons. The labs are also very good. I thought they were both educational and actually kinda fun to work in. I believe the course has something to offer both new analysts and veteran's alike. I've been doing forensic work for about 5 years now and make use of the Registry in most of my investigations. Still, I learned a great deal in this course and think most others will too.
Tuesday, September 10, 2013
Book Review: X-Ways Forensics Practitioner's Guide
X-Ways Forensics Practitioner's Guide
 As I’ve mentioned in previous reviews, there are only a few books I get truly excited about. The ones I actually pre-order are few and far between. However, I decided when I heard about this book I would pre-order it for sure. As it turned out, that wasn’t necessary. In the interest of full-disclosure, I want to say I got an advance copy for review and a quote from me appears on the back cover.
As I’ve mentioned in previous reviews, there are only a few books I get truly excited about. The ones I actually pre-order are few and far between. However, I decided when I heard about this book I would pre-order it for sure. As it turned out, that wasn’t necessary. In the interest of full-disclosure, I want to say I got an advance copy for review and a quote from me appears on the back cover.
I’ve been an X-Ways Forensics (XWF) user for just shy of four years. I’ll admit it now, I’m a fanboy. I love working with XWF and wouldn’t trade it for anything else. Despite having taken the XWF training course a few years ago, I’ve always felt like I wasn’t really using the software to its full potential. I was thrilled when co-author Brett Shavers told me about this book he was writing with Eric Zimmerman.
Shavers and Zimmerman are both well-known in the XWF community. I’ve seen their posts helping others and have received help from them myself when I’ve had questions about the software. I knew they were the right men for the job of writing this book.
XWF has a reputation (unfair in my opinion) of being difficult to use. Many practitioners are aware of how powerful the program is, but fear the dreaded learning curve. The X-Ways Forensics Practitioners Guide is meant to allay those fears, as well as teach veteran users a thing or two.
As an XWF user, I know the software is updated on a very frequent basis. According to the book:
"… there is an average of 41 days between new versions!". I wondered if this book could be written and truly remain relevant for long, given the regular updates and additions. After reading it, I believe the book will indeed remain relevant for future XWF versions. Though features are added and other things improved, the “basic” functionality of the program and the user interface remain familiar.
X-Ways Forensics Practitioners Guide has 10 chapters and two appendices. It begins with a brief history of X-Ways Forensics and its creator, Stefan Fleischmann. The intro also talks about the frequent XWF updates, as well as why they believe the book will be relevant and reliable guide for a long time to come. The remainder of the book is well organized and the chapters are logically arranged to get you from new user to completing an investigation.
Chapters one through three provide the reader with an excellent guide to getting the software installed and set up. One of the many things I like about the software is that you don’t have to actually install it. It will run from a usb thumb drive or from a complete install to Windows. The authors talk about the various ways XWF can be installed and run. The best way, in my opinion, is to “install” using the X-Ways Forensics Install Manager (XWFIM), a program written by book co-author Eric Zimmerman. XWFIM will download the version you wish to obtain, along with the appropriate viewer program. It also allows you to download the 32 bit, 64 bit or both versions and places them in the directory of your choice.
Chapter one also talks about setting up your dongle and introduces the user interface. It explains in nice detail what all the buttons are for. What I liked best about this chapter and the rest of the book, however, was the coverage of the various program options in which the authors provide their personal recommendations for the program settings. The program has so many choices, it’s helpful they provide these recommendations based on their own experience.
Chapter two covers Case Management and Imaging. The authors do a nice job of explaining how to set up a new case in XWF, explaining all the options in detail and offering advice on settings. They also cover the different types of disk imaging XWF can do and talk about file system support. I started using XWF for imaging about a year ago and like using it for that purpose. I have no numbers to back this up, but XWF just “seems faster” than other programs I’ve used for disk imaging. Again, the authors provide suggestions for optimal usage of the software.
Chapter two also talks about live response using XWF. I had the opportunity to use the program for that purpose not long ago when I was called to investigate a server intrusion with an unknown RAID configuration and owners unwilling to shut the server down. This type of use is covered, as is using a second instance of XWF to preview a system while your first instance is imaging the system during live response.
Chapter three is one of the most important chapters in the book. Extensive coverage of the program interface is provided, talking about left, middle and right click options, the Case Data Directory Tree and a great deal more. One part of the program I frequently find myself accessing is the Directory Browser Options, Filters dialog. The book covers each part of this dialog box and the authors again make recommendations for settings. XWF has, in many of its options, the choices of checked, unchecked or half-checked. These are described in detail and advice is given on how to make the most of them.
The next few chapters get into actually using the software. Using the Refine Volume Snapshot functions, hash databases and more are covered in chapters four and five.
One of the best, maybe the very best feature of XWF is the Refine Volume Snapshot function, covered in Chapter four. The RVS provides the means to perform file carving, extract file metadata and the contents of compressed files and more. Again, the book covers this feature in great detail, offering insight as to just what the volume snapshot is and what it means to refine it. Like all the chapters, screenshots of the various menus and options are included. A very nice graphic created by Ted Smith of the X-Ways Clips blog is included to help visualize the volume snapshot and refine volume snapshot functions.
The XWF Internal Hash Database and also the Registry Browser are talked about in Chapter five. I have used the hash database features since I first started using XWF, but I never used the Registry Browser. I normally rely on other software, such as RegDecoder and RegRipper for my registry investigation. I decided to give the XWF Registry Browser a look while reading this book and found it to be a pretty nice feature. Use of the hash database is explained very well, including how to create a database and the best ways to do your hashing.
Chapter six goes over the various means of searching using XWF. I’ve always known the search functions were very powerful, but I learned a lot from this chapter on ways I could search faster and with a greater likelihood of finding the data I’m searching for. I’ve always had difficulty grasping Regular Expressions and I was glad the authors took the time to cover their use in XWF. I came away from this chapter feeling like I had a much better chance of finding the data I need and with greater efficiency.
Advanced use of XWF is covered next. Ways to customize XWF configuration files, working with Hex and Timeline and Event Analysis is talked about through the first part of the chapter. Using the software to gather free and slack space is talked about next, along with RAM analysis. I had never used XWF for RAM analysis, preferring to use Volatility and perhaps occasionally Redline for that purpose. Once again, I learned some pretty good stuff about RAM analysis using XWF from this book and will definitely include the software in my investigations of RAM from here on.
One thing I had hoped to see in this book was a discussion of scripting for XWF. I’m not a programmer or script writer, but I have an interest in learning. While this is talked about somewhat, they are not covered as extensively as I had hoped. I do understand why they aren’t covered to a greater degree, as that would have deviated from the main point of the book and gotten into a how-to-program discussion.
The external analysis interface is next discussed. Again, I hadn’t used the function previously and learned how helpful it could be after reading this chapter.
Next up is Reporting in XWF. I’ve long appreciated the reporting capabilities and options in XWF and have used them many times. Just the same, I learned ways I could better take advantage of those capabilities.
The final two chapters cover the use of XWF in e-discovery and law enforcement investigations respectively. Methods of using the software to best conduct those investigations are talked about and suggestions/advice given. I’ve never done e-discovery, so I felt like I learned quite a bit from that chapter. The bulk of my forensics work is for Law Enforcement investigations and I found the chapter covered much of what I’d already been using the software for, although I’ll admit to learning a thing or two. Using XWF for on-scene triage is discussed, along with suggestions for use in probation searches. As pointed out in the book and as I’ve personally discovered, using XWF to triage a running system on-scene can be quite nice, helping you determine if full-disk encryption is in place.
Something else in the final chapter I have not yet tried is using XWF from a WinFE boot disk. I’ve not had much luck putting a WinFE disk together in the past, but admittedly haven’t spent a lot of time at it. Finally, Chapter 10 includes an example case to put what you’ve learned together in a practical sense.
Appendix A includes a nice collection of resources and shortcuts for XWF users. The great blogs of Ted Smith and Jimmy Weg are referred to, as well as a reference to some third party software. The remainder of this appendix is dedicated to keyboard shortcuts for use with XWF.
Finally, Appendix B is somewhat of an X-Ways FAQ chapter. This appendix is nice for a quick lookup of some commonly asked questions about the software.
Before ending this review, I wanted to talk about the writing style of the authors. This book doesn’t read like a dry, boring manual. It’s well written and easy to understand. I wonder sometimes how multiple authors can write a book and have it seem like it’s all written by one person. Cory and Harlan did a great job making Digital Forensics with Open Source Tools seem like a single author book and I have to say Brett and Eric did the same with this book. The text in both of those books flows well without seeming to jump from one person to another.
When I read a book and decide to review it, I ask myself a couple questions. First, did I learn from the book? Second, do I believe others will learn or benefit from the book? In this case, I have to say yes to both of those questions. This is the book the X-Ways community has needed for a long time. For those considering trying X-Ways, I strongly encourage you to buy this book. It will get you past the fear and trepidation some feel when they set out to use this great software and get you on the road to using it efficiently and successfully. For veteran users, I encourage you to buy it as well. As I said earlier, I’ve used XWF for nearly four years and feel quite comfortable with it. Still, I learned more than a just a little from reading this book and I’m betting you will too.

I’ve been an X-Ways Forensics (XWF) user for just shy of four years. I’ll admit it now, I’m a fanboy. I love working with XWF and wouldn’t trade it for anything else. Despite having taken the XWF training course a few years ago, I’ve always felt like I wasn’t really using the software to its full potential. I was thrilled when co-author Brett Shavers told me about this book he was writing with Eric Zimmerman.
Shavers and Zimmerman are both well-known in the XWF community. I’ve seen their posts helping others and have received help from them myself when I’ve had questions about the software. I knew they were the right men for the job of writing this book.
XWF has a reputation (unfair in my opinion) of being difficult to use. Many practitioners are aware of how powerful the program is, but fear the dreaded learning curve. The X-Ways Forensics Practitioners Guide is meant to allay those fears, as well as teach veteran users a thing or two.
As an XWF user, I know the software is updated on a very frequent basis. According to the book:
"… there is an average of 41 days between new versions!". I wondered if this book could be written and truly remain relevant for long, given the regular updates and additions. After reading it, I believe the book will indeed remain relevant for future XWF versions. Though features are added and other things improved, the “basic” functionality of the program and the user interface remain familiar.
X-Ways Forensics Practitioners Guide has 10 chapters and two appendices. It begins with a brief history of X-Ways Forensics and its creator, Stefan Fleischmann. The intro also talks about the frequent XWF updates, as well as why they believe the book will be relevant and reliable guide for a long time to come. The remainder of the book is well organized and the chapters are logically arranged to get you from new user to completing an investigation.
Chapters one through three provide the reader with an excellent guide to getting the software installed and set up. One of the many things I like about the software is that you don’t have to actually install it. It will run from a usb thumb drive or from a complete install to Windows. The authors talk about the various ways XWF can be installed and run. The best way, in my opinion, is to “install” using the X-Ways Forensics Install Manager (XWFIM), a program written by book co-author Eric Zimmerman. XWFIM will download the version you wish to obtain, along with the appropriate viewer program. It also allows you to download the 32 bit, 64 bit or both versions and places them in the directory of your choice.
Chapter one also talks about setting up your dongle and introduces the user interface. It explains in nice detail what all the buttons are for. What I liked best about this chapter and the rest of the book, however, was the coverage of the various program options in which the authors provide their personal recommendations for the program settings. The program has so many choices, it’s helpful they provide these recommendations based on their own experience.
Chapter two covers Case Management and Imaging. The authors do a nice job of explaining how to set up a new case in XWF, explaining all the options in detail and offering advice on settings. They also cover the different types of disk imaging XWF can do and talk about file system support. I started using XWF for imaging about a year ago and like using it for that purpose. I have no numbers to back this up, but XWF just “seems faster” than other programs I’ve used for disk imaging. Again, the authors provide suggestions for optimal usage of the software.
Chapter two also talks about live response using XWF. I had the opportunity to use the program for that purpose not long ago when I was called to investigate a server intrusion with an unknown RAID configuration and owners unwilling to shut the server down. This type of use is covered, as is using a second instance of XWF to preview a system while your first instance is imaging the system during live response.
Chapter three is one of the most important chapters in the book. Extensive coverage of the program interface is provided, talking about left, middle and right click options, the Case Data Directory Tree and a great deal more. One part of the program I frequently find myself accessing is the Directory Browser Options, Filters dialog. The book covers each part of this dialog box and the authors again make recommendations for settings. XWF has, in many of its options, the choices of checked, unchecked or half-checked. These are described in detail and advice is given on how to make the most of them.
The next few chapters get into actually using the software. Using the Refine Volume Snapshot functions, hash databases and more are covered in chapters four and five.
One of the best, maybe the very best feature of XWF is the Refine Volume Snapshot function, covered in Chapter four. The RVS provides the means to perform file carving, extract file metadata and the contents of compressed files and more. Again, the book covers this feature in great detail, offering insight as to just what the volume snapshot is and what it means to refine it. Like all the chapters, screenshots of the various menus and options are included. A very nice graphic created by Ted Smith of the X-Ways Clips blog is included to help visualize the volume snapshot and refine volume snapshot functions.
The XWF Internal Hash Database and also the Registry Browser are talked about in Chapter five. I have used the hash database features since I first started using XWF, but I never used the Registry Browser. I normally rely on other software, such as RegDecoder and RegRipper for my registry investigation. I decided to give the XWF Registry Browser a look while reading this book and found it to be a pretty nice feature. Use of the hash database is explained very well, including how to create a database and the best ways to do your hashing.
Chapter six goes over the various means of searching using XWF. I’ve always known the search functions were very powerful, but I learned a lot from this chapter on ways I could search faster and with a greater likelihood of finding the data I’m searching for. I’ve always had difficulty grasping Regular Expressions and I was glad the authors took the time to cover their use in XWF. I came away from this chapter feeling like I had a much better chance of finding the data I need and with greater efficiency.
Advanced use of XWF is covered next. Ways to customize XWF configuration files, working with Hex and Timeline and Event Analysis is talked about through the first part of the chapter. Using the software to gather free and slack space is talked about next, along with RAM analysis. I had never used XWF for RAM analysis, preferring to use Volatility and perhaps occasionally Redline for that purpose. Once again, I learned some pretty good stuff about RAM analysis using XWF from this book and will definitely include the software in my investigations of RAM from here on.
One thing I had hoped to see in this book was a discussion of scripting for XWF. I’m not a programmer or script writer, but I have an interest in learning. While this is talked about somewhat, they are not covered as extensively as I had hoped. I do understand why they aren’t covered to a greater degree, as that would have deviated from the main point of the book and gotten into a how-to-program discussion.
The external analysis interface is next discussed. Again, I hadn’t used the function previously and learned how helpful it could be after reading this chapter.
Next up is Reporting in XWF. I’ve long appreciated the reporting capabilities and options in XWF and have used them many times. Just the same, I learned ways I could better take advantage of those capabilities.
The final two chapters cover the use of XWF in e-discovery and law enforcement investigations respectively. Methods of using the software to best conduct those investigations are talked about and suggestions/advice given. I’ve never done e-discovery, so I felt like I learned quite a bit from that chapter. The bulk of my forensics work is for Law Enforcement investigations and I found the chapter covered much of what I’d already been using the software for, although I’ll admit to learning a thing or two. Using XWF for on-scene triage is discussed, along with suggestions for use in probation searches. As pointed out in the book and as I’ve personally discovered, using XWF to triage a running system on-scene can be quite nice, helping you determine if full-disk encryption is in place.
Something else in the final chapter I have not yet tried is using XWF from a WinFE boot disk. I’ve not had much luck putting a WinFE disk together in the past, but admittedly haven’t spent a lot of time at it. Finally, Chapter 10 includes an example case to put what you’ve learned together in a practical sense.
Appendix A includes a nice collection of resources and shortcuts for XWF users. The great blogs of Ted Smith and Jimmy Weg are referred to, as well as a reference to some third party software. The remainder of this appendix is dedicated to keyboard shortcuts for use with XWF.
Finally, Appendix B is somewhat of an X-Ways FAQ chapter. This appendix is nice for a quick lookup of some commonly asked questions about the software.
Before ending this review, I wanted to talk about the writing style of the authors. This book doesn’t read like a dry, boring manual. It’s well written and easy to understand. I wonder sometimes how multiple authors can write a book and have it seem like it’s all written by one person. Cory and Harlan did a great job making Digital Forensics with Open Source Tools seem like a single author book and I have to say Brett and Eric did the same with this book. The text in both of those books flows well without seeming to jump from one person to another.
When I read a book and decide to review it, I ask myself a couple questions. First, did I learn from the book? Second, do I believe others will learn or benefit from the book? In this case, I have to say yes to both of those questions. This is the book the X-Ways community has needed for a long time. For those considering trying X-Ways, I strongly encourage you to buy this book. It will get you past the fear and trepidation some feel when they set out to use this great software and get you on the road to using it efficiently and successfully. For veteran users, I encourage you to buy it as well. As I said earlier, I’ve used XWF for nearly four years and feel quite comfortable with it. Still, I learned more than a just a little from reading this book and I’m betting you will too.
Thursday, July 11, 2013
Thank You's, links and stuff
Hello everyone; hope your summer is going well. I continue to await moving into our new home, so I'm not doing much in the way of testing or working on things for new blog posts. I should be all set up in my new home lab in about 6 weeks. In the meantime, I've been given some exciting opportunities that I'll be blogging about in the near future. Can't tell you what they are yet, but when I'm allowed to do so I'll be posting.
I received a quite pleasant and unexpected surprise Tuesday when I learned this blog won the Forensic 4cast Award for Digital Forensic Blog of the Year. I want to thank everyone who voted for me and congratulate all the other winners and nominees. I especially want to thank Lee Whitfield for putting the awards together each year. I know it's a lot of stress and work and I know the entire community appreciates your efforts.
Finally, I wanted to provide links to several blog posts of interest I've read recently. Harlan has been hitting quite a few home runs lately with his HowTo series of posts. I love posts like these, as they provide information you can put to use right now.
The most recent post on Harlan's blog is Programming and DFIR. He talks about why having at least a basic level of programming knowledge can be so helpful to a DFIR analyst. He points out how having that understanding can help you break down the goals of your case into smaller, achievable tasks. Furthermore, coding allows you to automate some of your regular tasks; something I think we could all benefit from.
I'll admit, I've promised myself on a number of occasions that I was going to learn to program. Back in high school, I had a Radio Shack Color Computer 2 (and later the 3) and I did a little BASIC programming. I later became interested in traffic crash reconstruction and I wrote a BASIC program to calculate a vehicle's speed from its skid marks, based on the distance of the skid, the drag factor of the roadway and some other data I've long since forgotten. What was cool was that after writing that little program, I didn't have to manually calculate the speed anymore. The point is, writing one simple little program automated the calculation process every single time. No more algebra. I never liked algebra anyway ;-)
I've known for a long time that learning to script/code could help me do my work faster and with more efficiency, but for whatever reason I just never have stuck with it. I've started trying to learn Perl and Python, but seem to always get lost and give up after a time. I'm going to give it another try, I think, and hopefully stick with it.
David Cowen has started a blog a day for a year challenge on his Hacking Exposed Computer Forensics Blog. He's been doing a DFIR career milestones series, as well as talking about the NTFS TriForce research he's been doing. The milestone posts, along with Harlan's post are what have inspired me to once again try my hand at coding. David's posts are always very interesting. Also, congratulations to him for his 4cast award for Blog Post of the Year.
Dan has a great new post on UserAssist artifacts in forensic analysis. His posts are always well researched and written. He does a great job explaining (in all his posts) why the material is important and how it can be of use in your investigations.
Adam has a very well researched and explained post on his blog on GPS forensics. He details his examination of Garmin Nüvi 1490 and all the artifacts he found. I found the information presented on his research to be very interesting. I recently attended the BlackThorn GPS Forensics course and learned quite a bit, but I found Adam's post definitely helped me understand some areas better, especially with regard to the structure of the gpx files and their timestamps.
The SANS Digital Forensic and Incident Response Summit in Austin, Tx just concluded. I had to miss it this year, unfortunately. The speaker lineup looked phenomenal and the networking is always fantastic. Rob Lee and the SANS crew do a fantastic job with the Summit each year. Hope I can return next year.
That's all I have for now. Thank you again to all who voted in the 4cast awards, whether you voted for me or not. The awards are a great thing for our little community and I'm glad to see them continue.
I received a quite pleasant and unexpected surprise Tuesday when I learned this blog won the Forensic 4cast Award for Digital Forensic Blog of the Year. I want to thank everyone who voted for me and congratulate all the other winners and nominees. I especially want to thank Lee Whitfield for putting the awards together each year. I know it's a lot of stress and work and I know the entire community appreciates your efforts.
Finally, I wanted to provide links to several blog posts of interest I've read recently. Harlan has been hitting quite a few home runs lately with his HowTo series of posts. I love posts like these, as they provide information you can put to use right now.
The most recent post on Harlan's blog is Programming and DFIR. He talks about why having at least a basic level of programming knowledge can be so helpful to a DFIR analyst. He points out how having that understanding can help you break down the goals of your case into smaller, achievable tasks. Furthermore, coding allows you to automate some of your regular tasks; something I think we could all benefit from.
I'll admit, I've promised myself on a number of occasions that I was going to learn to program. Back in high school, I had a Radio Shack Color Computer 2 (and later the 3) and I did a little BASIC programming. I later became interested in traffic crash reconstruction and I wrote a BASIC program to calculate a vehicle's speed from its skid marks, based on the distance of the skid, the drag factor of the roadway and some other data I've long since forgotten. What was cool was that after writing that little program, I didn't have to manually calculate the speed anymore. The point is, writing one simple little program automated the calculation process every single time. No more algebra. I never liked algebra anyway ;-)
I've known for a long time that learning to script/code could help me do my work faster and with more efficiency, but for whatever reason I just never have stuck with it. I've started trying to learn Perl and Python, but seem to always get lost and give up after a time. I'm going to give it another try, I think, and hopefully stick with it.
David Cowen has started a blog a day for a year challenge on his Hacking Exposed Computer Forensics Blog. He's been doing a DFIR career milestones series, as well as talking about the NTFS TriForce research he's been doing. The milestone posts, along with Harlan's post are what have inspired me to once again try my hand at coding. David's posts are always very interesting. Also, congratulations to him for his 4cast award for Blog Post of the Year.
Dan has a great new post on UserAssist artifacts in forensic analysis. His posts are always well researched and written. He does a great job explaining (in all his posts) why the material is important and how it can be of use in your investigations.
Adam has a very well researched and explained post on his blog on GPS forensics. He details his examination of Garmin Nüvi 1490 and all the artifacts he found. I found the information presented on his research to be very interesting. I recently attended the BlackThorn GPS Forensics course and learned quite a bit, but I found Adam's post definitely helped me understand some areas better, especially with regard to the structure of the gpx files and their timestamps.
The SANS Digital Forensic and Incident Response Summit in Austin, Tx just concluded. I had to miss it this year, unfortunately. The speaker lineup looked phenomenal and the networking is always fantastic. Rob Lee and the SANS crew do a fantastic job with the Summit each year. Hope I can return next year.
That's all I have for now. Thank you again to all who voted in the 4cast awards, whether you voted for me or not. The awards are a great thing for our little community and I'm glad to see them continue.
Monday, May 27, 2013
This 'n That
Hello world! I wanted to let you know why I haven't been putting up any new posts lately and also tell you about some great stuff on other blogs.
First, I haven't been posting as all my computer equipment is in storage at my parents house, so I have no way of running any new projects at the moment. We sold our house and are in between homes as we wait for our new home out on the farm. Once we get moved in, I plan to set up my equipment and get back to blogging.
In the meantime, I would welcome guest posts if you're itching to write and don't have a blog of your own. My only rules are that your post is about forensics, infosec or malware and that you can back up anything you say in your post. I'm not overly strict on the topics, so if you have a topic you think might fit in here, let me know and we'll talk about it. You can contact me at kdpryor {at} gmail [dot] com.
And now, some links!
David Cowen posted about his CEIC presentation on the NTFS Triforce and provided a link to sign up for the public beta. You can find the post HERE. He includes a link to sign up for the public beta test, as well as links for his slides, labs and a demo video on YouTube.
David's new book, Computer Forensics Infosec Pro Guide, came out recently, as well. I haven't got to read it, yet, but hope to soon. The reviews on Amazon are quite favorable, which is no surprise. David is an excellent writer and a forensics expert, as well as being a really good guy.
Corey Harrell posted about a new tool he's released called autorip. More importantly, he talks about his process when conducting an investigation and letting it dictate the tool usage and not the other way around. Corey is one of the smartest people I know and I always learn from him. You can read his new post at http://journeyintoir.blogspot.com/2013/05/unleashing-autorip.html .
An upcoming book I'm very excited about is the X-Ways Forensics Practitioners Guide from Syngress. I've used X-Ways for about four years now and love working with it. X-Ways has a reputation with some of being a bit hard to learn, even with the extensive user manual. This new book should help both the veteran user and the newcomer learn how to take advantage of this powerful software. The book is being written by Brett Shavers and Eric Zimmerman, while Jimmy Weg is the tech editor. All three of these gentlemen are highly respected in the forensics community overall and active in the X-Ways user community. They clearly know the subject and I have no doubt the book will be very good. I'll be reviewing the book as soon as I get a chance to read it.
The Volatility Labs team is holding Month of Volatility Plugins 2 this month. Check out their blog for all the great new posts coming from the awesome Volatility crew.
Finally, voting is coming to a close soon for the Forensic 4cast Awards. Be sure to go cast your vote before it's too late.
In the meantime, I would welcome guest posts if you're itching to write and don't have a blog of your own. My only rules are that your post is about forensics, infosec or malware and that you can back up anything you say in your post. I'm not overly strict on the topics, so if you have a topic you think might fit in here, let me know and we'll talk about it. You can contact me at kdpryor {at}
Corey Harrell posted about a new tool he's released called autorip. More importantly, he talks about his process when conducting an investigation and letting it dictate the tool usage and not the other way around. Corey is one of the smartest people I know and I always learn from him. You can read his new post at http://journeyintoir.blogspot.com/2013/05/unleashing-autorip.html .
An upcoming book I'm very excited about is the X-Ways Forensics Practitioners Guide from Syngress. I've used X-Ways for about four years now and love working with it. X-Ways has a reputation with some of being a bit hard to learn, even with the extensive user manual. This new book should help both the veteran user and the newcomer learn how to take advantage of this powerful software. The book is being written by Brett Shavers and Eric Zimmerman, while Jimmy Weg is the tech editor. All three of these gentlemen are highly respected in the forensics community overall and active in the X-Ways user community. They clearly know the subject and I have no doubt the book will be very good. I'll be reviewing the book as soon as I get a chance to read it.
The Volatility Labs team is holding Month of Volatility Plugins 2 this month. Check out their blog for all the great new posts coming from the awesome Volatility crew.
Finally, voting is coming to a close soon for the Forensic 4cast Awards. Be sure to go cast your vote before it's too late.
Wednesday, April 10, 2013
NBDServer
A project I read about a while back really caught my attention, but I hadn't had a good chance to try it out till recently. Jeff Bryner (@p0wnlabs) created NBDServer and describes it as a "A DFIR/forensic take on nbdsrvr by Folkert van Heusden."
In essence, NBDServer allows you to set up a server on a Windows machine (XP, Win 7, Win 2008) and then connect to it from a Linux client. The client configures the Windows server as a read-only network block device, allowing you to mount the device on the client like a local disk, image it across the network or run other forensic tools on the device. It is also possible to use this tool in conjunction with the Volatility winpmem utility to image the Windows system RAM across the network to your client.
Running NBDServer is simple. There is no real setup, so all you have to do is download the ZIP file, extract the contents and place them on the Windows machine you wish to work with. You'll need to run the program from an Administrative command prompt (gasp! a command line program!) if using Windows Vista, 7, 2008, etc. I'll come back to the mechanics of running NBDServer in a moment, but first let's talk about setting up the Linux client.
The Linux half of this setup, known as nbd-client, available from it's page on Sourceforge and is apparently created and maintained by Wouter Verhelst. Download the nbd-client package (currently version 3.2) to your Linux workstation and install it using the typical ./configure && make && make install. I installed it to the new Kali Linux and didn't have to account for any missing dependencies, but your mileage may vary on a different distro. Once installed run "modprobe nbd" to initialize the new device prior to attempting to connect with the server.
To test the setup, I ran it from several different configurations. The first test used a Kali Linux virtual machine and a Windows XP Pro virtual machine on the same host. After that, I used two physical machines, being Kali Linux installed to hard drive on one pc and Windows 7, 64-bit on the other. Finally, I connected between the Windows XP Pro vm and the physical Kali Linux box. I tested the ability to connect and remain connected, as well as mounting remote drives and imaging disks and RAM via the network. I won't detail every result from each separately, as they were all essentially the same. I will cover imaging RAM separately a little later in this post.
To begin simulating a response to a Windows machine, I connected my Linux box to a network share which the subject Windows pc could also connect to. I copied the nbdserver.exe to a folder on the share and then opened the share on the Windows machine (x: drive on this machine) and copied the nbdserver to the desktop. On the Win 7 pc, I opened an Administrative command prompt and navigated to the nbdserver location. I reviewed the available options from the README which include:
Usage:
On the first attempt, I wanted to connect to the system drive on the Win 7 machine and mount it in Linux. The IP address for the Windows box was 192.168.2.157 and the Linux IP was 192.168.2.197. So, my command line was as such:
This instructs the server to connect to the client IP and serve up the first partition on drive 0. I hit enter and the program started, though all you see is the cursor drop to the next line and sit there flashing. No news is good news at this point.
I moved over to the Linux pc to start the client. You may need to use sudo when running it. The command for starting the client is as follows:
followed by
(sudo) nbd-client -d /dev/nbd0
In essence, NBDServer allows you to set up a server on a Windows machine (XP, Win 7, Win 2008) and then connect to it from a Linux client. The client configures the Windows server as a read-only network block device, allowing you to mount the device on the client like a local disk, image it across the network or run other forensic tools on the device. It is also possible to use this tool in conjunction with the Volatility winpmem utility to image the Windows system RAM across the network to your client.
Running NBDServer is simple. There is no real setup, so all you have to do is download the ZIP file, extract the contents and place them on the Windows machine you wish to work with. You'll need to run the program from an Administrative command prompt (gasp! a command line program!) if using Windows Vista, 7, 2008, etc. I'll come back to the mechanics of running NBDServer in a moment, but first let's talk about setting up the Linux client.
The Linux half of this setup, known as nbd-client, available from it's page on Sourceforge and is apparently created and maintained by Wouter Verhelst. Download the nbd-client package (currently version 3.2) to your Linux workstation and install it using the typical ./configure && make && make install. I installed it to the new Kali Linux and didn't have to account for any missing dependencies, but your mileage may vary on a different distro. Once installed run "modprobe nbd" to initialize the new device prior to attempting to connect with the server.
To test the setup, I ran it from several different configurations. The first test used a Kali Linux virtual machine and a Windows XP Pro virtual machine on the same host. After that, I used two physical machines, being Kali Linux installed to hard drive on one pc and Windows 7, 64-bit on the other. Finally, I connected between the Windows XP Pro vm and the physical Kali Linux box. I tested the ability to connect and remain connected, as well as mounting remote drives and imaging disks and RAM via the network. I won't detail every result from each separately, as they were all essentially the same. I will cover imaging RAM separately a little later in this post.
To begin simulating a response to a Windows machine, I connected my Linux box to a network share which the subject Windows pc could also connect to. I copied the nbdserver.exe to a folder on the share and then opened the share on the Windows machine (x: drive on this machine) and copied the nbdserver to the desktop. On the Win 7 pc, I opened an Administrative command prompt and navigated to the nbdserver location. I reviewed the available options from the README which include:
Usage:
NBDServer.exe v3.0
-c Client IP address to accept connections from
-p Port to listen on (60000 by default)
-f File to serve ( \\.\PHYSICALDRIVE0 or \\.\pmem for example)
-n Partition on disk to serve (0 if not specified)
-w Enable writing (disabled by default)
-d Enable debug messages
-q Be Quiet..no messages
-h This help text
-f option supports names like the following:
\\.\PHYSICALDRIVE0 raw drive partition access along with -n option
\\.\C: volume access (no need for -n option)
\\.\HarddiskVolume1 volume access (no need for -n option)
afile.dd serve up the contents of 'afile.dd' via nbd.
\\.\pmem access the pmem memory driver from volatility
On the first attempt, I wanted to connect to the system drive on the Win 7 machine and mount it in Linux. The IP address for the Windows box was 192.168.2.157 and the Linux IP was 192.168.2.197. So, my command line was as such:
nbdserver.exe -c 192.168.2.197 -f \\.\PHYSICALDRIVE0 -n0
This instructs the server to connect to the client IP and serve up the first partition on drive 0. I hit enter and the program started, though all you see is the cursor drop to the next line and sit there flashing. No news is good news at this point.
I moved over to the Linux pc to start the client. You may need to use sudo when running it. The command for starting the client is as follows:
modprobe nbd
followed by
(sudo) nbd-client 192.168.2.157 60000 /dev/nbd0
This starts the client, tells it to look for the server on 192.168.2.157, use
port 60000 and create the new network block device as /dev/nbd0.
Upon executing the above commands, the connection was successfully established as evidenced by messages displayed on both machines command lines. The Windows side just reports a successful connection to the client IP. The client showed the size of the new device in megabytes and bytes, as well as the block size.
I next ran the fls tool from the Sleuth Kit to generate a quick timeline on the new block device like this:
fls -f ntfs -m C: -r /dev/nbd0 > test.fls
This worked with no problem, so my next test was to mount the device in Linux. I typed the following command:
mount -t ntfs-3g -o rw,show_sys_files,streams_interface=windows /dev/nbd0 /mnt/nbd
You may have noticed I included "rw" for read/write instead of "ro" for read-only. I wanted to test and make sure that nbdserver really was only giving me read-only access to the disk, regardless of how I mounted it. I created a text file using the touch command while in the mounted Windows user directory, then opened it and added some text to it. I save it and type ls, seeing it was listed among the files in the directory. I looked over to the real Windows machine to see if the file was there, but it wasn't. Back on the Linux side, I typed rm -rf * for everything in the current directory and typed ls, showing an empty directory. However, looking at the real folder on the Windows machine showed nothing was added and nothing was deleted.
I issued a umount command to unmount the device, then disconnected from the server with this command:
(sudo) nbd-client -d /dev/nbd0
A quick ctrl-C on the Windows side killed the server. I then re-connected and again mounted the system drive, finding all files were where they were supposed to be and no additional files had been created. The nbdserver/client setup appears to create and delete files on your command, but nothing actually changes.
Using the same methods described already, I also accessed a USB flash drive. I was able to mount and imag it across the network with no issues.
As I mentioned above, it's also possible to image RAM on the Windows system via the network with nbdserver. In addition to the server, you also need the latest version of winpmem from the awesome Volatility project. The current winpmem.exe version is 1.4.1.
Prior to starting the server, it is necessary to load the winpmem driver. You can do this manually, but there's really no need. The winpmem executable works very well and is invoked by typing:
winpmem_1.4.exe -l (that's a lowercase L, not a number 1)
If you see no errors after running that, you should be ready to continue. Start your nbdserver as before, but this time you'll change what you're telling the server to make available to the client. Your new command line will look something like:
nbdserver.exe -c 192.168.2.197 -f \\.\pmem
Over on the client, you can pretty much type the same thing you did before. You can add the -b option to designate the block size also. Here's an example:
nbd-client 192.168.2.157 60000 /dev/nbd1 -b 1024
You can then use your favorite version of dd, dc3dd, dcfldd, etc, to image the RAM device like this:
dc3dd if=/dev/nbd1 of=./physmem.raw (name it whatever you want)
From there, you can use Volatility to work with your RAM image. Just to make sure I got a good image, I ran the Volatility kdbgscan plugin on the ram image. It reported correct information, so I knew I was in good shape.
The only issue I ran into imaging RAM involved the 64-bit Win 7 machine. Imaging memory on the XP Pro machine worked without a hitch. However, I found the 64-bit machine would lock up and then spontaneously reboot when the imaging reached 3.5GB of the 12GB total. I plan to contact Volatility and let them know and will be happy to provide any sample data to help figure out what went wrong.
Overall, I would call this a huge success. Except for the 64-bit RAM imaging issue, I experienced no problems I couldn't attribute to user error. If you find yourself in need of a tool like this and don't have to money or time to obtain a commerical product like F-Response, I think you'll find you can accomplish what you need with NBDServer.
NOTE: Edited to remove some content I want to test further.
NOTE: Edited to remove some content I want to test further.
Thursday, April 4, 2013
Forensic 4cast Awards
I wanted to let you all know that voting has begun for this years Forensic 4cast awards. I'm pleased to say this blog received a nomination for the Digital Forensic Blog of the Year. As happy as I would be to win, I must admit the two other nominees are far better choices and deserve your votes. I have a good time writing here, but this blog is not in the same league as Corey's Journey Into Incident Response blog or the Volatility Labs blog. Both of them devote a lot of time to research and blogging. I'm deeply appreciative for the nomination and I hope to produce something worth an award sometime, but I encourage you to vote for Corey or Volatility.
On another topic, I've been testing Jeff Bryner's NBDServer the last couple days. It's pretty cool, but I've got a couple issues to figure out. I've used it successfully between two virtual machines and also between one VM and the host system, but I'm having trouble getting it to work between two physical machines. I'll do a blog post about it once I get everything figured out.
Saturday, March 23, 2013
Working Smarter, Not Harder
There are a couple reasons I enjoy blogging, although my lack of frequent posts would suggest I don't like it that much. Just the same, I do it because I enjoy writing and I find writing something down like this helps me remember it for the next time I need it. If this helps someone else in the process, then so much the better.
I've been working on an intrusion case recently, something I've previously done only in training. I have already started a separate blog post talking about it, but I'm not really ready to finish it yet. However, I wanted to post today about something I should have been doing all along. I've used such great tools as Volatility, Log2Timeline and the SANS Forensics SIFT Workstation on this case, as well as RegRipper. RegRipper is what I wanted to talk about today.
The developer of RegRipper, Harlan Carvey, made a new post on his blog recently about finding evidence of program execution on a system under investigation. As a police officer, most of my cases revolve around finding the porn, trying to figure out how it got there and if it's been viewed. Not terribly difficult, most of the time. I rarely have the need to determine whether or not a particular program has been run. Even in the case of investigating child exploitation video possession, I can usually determine if a video has been viewed through .lnk files, jump lists, recent docs, application history and so on. I was able to determine on a recent case that a particular video had been opened in RealPlayer by finding the .lnk file RealPlayer creates upon playing a file. That, along with timeline evidence and some application testing helped prove the case. But, I digress.
As I said, it's not often that program execution is that important to my cases. I found the need to do this, however, after discovering the intruders in this particular case had downloaded several things to the victim Windows 2008 system, including some hacking tools, a bulk email sender and several different web browsers. While I found ample web history to easily show the browsers had been used, I wanted to find out if the other programs had been only downloaded or actually used. Harlan's post helped me remember some steps I could take and taught me some new ones as well to help figure this out.
That was the set up, but here's the real point of this post. I found myself using RegRipper in my quest to determine program execution. I use the command line rip.exe probably as much, maybe more often than the RegRipper GUI. The problem is, I was using the program in a less than efficient manner. Instead of taking advantage of the ability to create a custom profile and running all the plugins I was interested in at once, I was typing them each in at the command line one at a time, looking at the output and then running another. This amounts to an inefficient use of the fleeting time I have to work only on forensic cases. My job is such that I frequently get called out from my DFIR work to answer regular "routine" calls for service, car wrecks, domestic disputes, etc. Running one little command at a time instead of preparing a custom profile is just silly and creates unnecessary delay.
Harlan asked me what could be done to get users to run all needed plugins at once instead of doing one and then waiting to do the another later. I think the answer to that, at least in my case, is just reminding myself that there are better, easier ways to do things sometimes than the way I choose.
It's helpful to plan ahead what you may be interested in. The plugins available from the RegRipper Plugins site include the individual plugins applicable to each of the registry hives and a couple plugins that can be used against all the hives. Also included are "all" plugin profiles for each hive, such as one for ntuser-all, system-all and so on. These profiles have every included plugin listed in them and when run via RegRipper, will run every plugin listed in them against the hive file you've indicated. Running rip.exe -r ntuser.dat -f ntuser-all, for example, will run every ntuser.dat specific plugin against the ntuser.dat file.
Creating a custom profile for RegRipper and/or rip.exe is dead simple. The great thing about these profiles is they are just text files, easily edited in your favorite text editor. I decided to create a custom profile for this post and will tell you how I did it.
I used FTK Imager to grab the ntuser.dat file from this system and saved it to a test folder. I next selected at random several plugins in the plugins folder that are used to parse the ntuser.dat file for specific information. In my new blank text file, I typed the following:
#test custom plugin profile
#
userassist
domains
ccleaner
I closed my text file and saved it as kptest. You can call it what you want, I suppose, but that's what I used. Notice the plugins are listed in this profile without the .pl extension. Likewise, whether you run a single plugin at the command line or create a profile, you'll want to leave off the .pl. RegRipper takes care of adding that. That's it. It's that easy.
So, to try out my new test profile, I went to the command line and typed the following (in the same directory where my ntuser.dat copy was stored): rip.exe -r ntuser.dat -f kptest > test.txt. This ran only the plugins I defined in the "kptest" profile against the ntuser.dat file in that directory. This same test profile was available in the RegRipper GUI and produced the same results. The GUI also produces a log file in addition to the output.
So, why do this? Why not just run the included profiles? The answer to that is "information overload". The "all" profiles produce a lot of information, often more than you really need. Making your own profile on a case by case basis, based on your needs to that particular case will save you from sifting through lots of information you don't want or need. Sometimes you may discover you need to run other plugins after doing this and that's fine, but why not try to do as much as you can at one time and then follow up with others later if necessary?
As I said, I write this as much to help me remember it as I do to help others. If you gained something from this post, then I'm very happy about that.
I will be posting again soon about the same investigation I mentioned above. It has all sorts of "win" through the use of FOSS tools and I look forward to telling you about it.
Thursday, January 3, 2013
And now for something completely different...HoneyDrive
For quite a while now, I've wanted to set up a honeypot and see what I can learn from it. I was happy to find out that the Ion at BruteForce Labs has put together a great "all in one" virtual machine with preconfigured honeypots. The virtual machine is called HoneyDrive. Upon learning about it, I decided this was as good a time as any to try out running a honeypot.
HoneyDrive makes it incredibly easy to get started. It includes Kippo, Dionaea, Honeyd and LaBrea honeypots, as well as lots of related software tools, including (from the website) "A full suite of security, forensics and anti-malware tools for network monitoring, malicious shellcode and PDF analysis, such as ntop, p0f, EtherApe, nmap, DFF, Wireshark, ClamAV, ettercap, Automater, UPX, pdftk, Flasm, pdf-parser, Pyew, dex2jar and more." As you can see, it's packed full of great stuff.
It is ready for download as a VirtualBox .ova file, so all you have to do is open VirtualBox, click File-Import Appliance and select the HoneyDrive .ova file. Once the import is finished, you will have a new, ready to run HoneyDrive vm available in your inventory. Then, just configure its settings and start it up.
I changed a few of the settings prior to first run. I changed the network settings to make sure it would bind to the correct network card, as I have more than one in the host machine and wanted to have it on the correct network. I also bumped up the ram for the vm a little. I won't go in to how to do these things, as they are pretty basic changes for anyone who has previously used VirtualBox.
After starting up the machine and verifying my networking was set up right, I was ready to get started. The next decision was, which honeypot would I try first? My good friend Leon van der Eijk has written on his blog and spoken about his work with the Kippo ssh honeypot. Likewise, Andrew Waite has posted quite a bit about Kippo and Dionaea on his InfoSanity blog. They are my "go to" guys when I have a honeypot question.
I decided to go with Dionaea to begin with, as I've been wanting to try a honeypot for the purpose of malware collection. Setup of Dionaea in HoneyDrive is quite easy, although I found it was unable to bind to port 80 at first. I discovered Apache webserver was running by default on HoneyDrive and it was interfering with Dionaea and port 80, so I shut down Apache and all worked well from there. Well, almost all.
As I said, my goal with Dionaea was to collect malware. Unfortunately, my Internet service provider apparently filters port 445 (SMB/CIFS), so I got no connections at all on that port and no files accordingly. I did get lots of connections on ports 80, 443, 1433 and 3306, however, so it wasn't a total loss. The majority of IP addresses connecting to those ports were from (big surprise) China. I left Dionaea running for a couple days and then decided I wanted to try out Kippo.
Kippo is an ssh honeypot. It has a fake filesystem, simulating a Debian Linux server and that is what the attacker sees on login. They can navigate around, but can't do any real damage. It is absolutely simple to get started in HoneyDrive and I saw almost immediate results. Ion has created some great ways to monitor your Kippo with custom made scripts and the ability to view your Kippo stats via web browser (see pics).

Above, you see the initial start screen for Ion's Kippo-Graph. The results aren't delivered in real-time, so you have to click "Generate The Kippo Graphs". What follows is incredibly detailed information. There is much more to Kippo Graph than you'll see in the following pictures, but they will at least give you a taste of what's available.
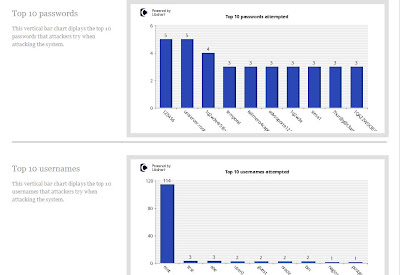


Kippo has only been running for about a day as of this writing, so there aren't lots of stats yet. Still, it appears some have shown some interest in trying to log in. A few of the logins are mine, just testing from various IP addresses, but the bulk of login attempts are from other countries.
One amazing thing about Kippo is the ability to play back "recordings" of logins. When someone logs in to the Kippo fake filesystem and tries to navigate around what they think is a server of some sort, Kippo records their every move and saves it to a log file. You may then use the playlog.py utility to replay the attacker's activity, just like you recorded it on your DVR. You can see every command they typed, seeing it just like you were watching them live at the console. Kippo will be sure to save a copy of any files they download to it. For whatever reason, no one has done more than attempt to log in so far, despite the simple password, so I have no log replays to show you right now. When I finally get a good one, I'll post it here so you can see how it works.
Tektip has some good videos on HoneyDrive and Kippo too. I recommend you watch them to get a greater feel for how all this works. I plan to try out some of the other honeypots in Honeydrive soon, but I'm currently enjoying working with Kippo. I'll probably try out Honeyd in the next couple days, however.
If you've always been curious about running a honeypot, I can't recommend HoneyDrive strongly enough. It is, without a doubt, the fastest and easiest way to get started. Congratulations and thanks to Ion for putting it all together. Thanks also to all the honeypot and other tool developers whose work is included in HoneyDrive.
HoneyDrive makes it incredibly easy to get started. It includes Kippo, Dionaea, Honeyd and LaBrea honeypots, as well as lots of related software tools, including (from the website) "A full suite of security, forensics and anti-malware tools for network monitoring, malicious shellcode and PDF analysis, such as ntop, p0f, EtherApe, nmap, DFF, Wireshark, ClamAV, ettercap, Automater, UPX, pdftk, Flasm, pdf-parser, Pyew, dex2jar and more." As you can see, it's packed full of great stuff.
It is ready for download as a VirtualBox .ova file, so all you have to do is open VirtualBox, click File-Import Appliance and select the HoneyDrive .ova file. Once the import is finished, you will have a new, ready to run HoneyDrive vm available in your inventory. Then, just configure its settings and start it up.
I changed a few of the settings prior to first run. I changed the network settings to make sure it would bind to the correct network card, as I have more than one in the host machine and wanted to have it on the correct network. I also bumped up the ram for the vm a little. I won't go in to how to do these things, as they are pretty basic changes for anyone who has previously used VirtualBox.
After starting up the machine and verifying my networking was set up right, I was ready to get started. The next decision was, which honeypot would I try first? My good friend Leon van der Eijk has written on his blog and spoken about his work with the Kippo ssh honeypot. Likewise, Andrew Waite has posted quite a bit about Kippo and Dionaea on his InfoSanity blog. They are my "go to" guys when I have a honeypot question.
I decided to go with Dionaea to begin with, as I've been wanting to try a honeypot for the purpose of malware collection. Setup of Dionaea in HoneyDrive is quite easy, although I found it was unable to bind to port 80 at first. I discovered Apache webserver was running by default on HoneyDrive and it was interfering with Dionaea and port 80, so I shut down Apache and all worked well from there. Well, almost all.
As I said, my goal with Dionaea was to collect malware. Unfortunately, my Internet service provider apparently filters port 445 (SMB/CIFS), so I got no connections at all on that port and no files accordingly. I did get lots of connections on ports 80, 443, 1433 and 3306, however, so it wasn't a total loss. The majority of IP addresses connecting to those ports were from (big surprise) China. I left Dionaea running for a couple days and then decided I wanted to try out Kippo.
Kippo is an ssh honeypot. It has a fake filesystem, simulating a Debian Linux server and that is what the attacker sees on login. They can navigate around, but can't do any real damage. It is absolutely simple to get started in HoneyDrive and I saw almost immediate results. Ion has created some great ways to monitor your Kippo with custom made scripts and the ability to view your Kippo stats via web browser (see pics).

Above, you see the initial start screen for Ion's Kippo-Graph. The results aren't delivered in real-time, so you have to click "Generate The Kippo Graphs". What follows is incredibly detailed information. There is much more to Kippo Graph than you'll see in the following pictures, but they will at least give you a taste of what's available.



One amazing thing about Kippo is the ability to play back "recordings" of logins. When someone logs in to the Kippo fake filesystem and tries to navigate around what they think is a server of some sort, Kippo records their every move and saves it to a log file. You may then use the playlog.py utility to replay the attacker's activity, just like you recorded it on your DVR. You can see every command they typed, seeing it just like you were watching them live at the console. Kippo will be sure to save a copy of any files they download to it. For whatever reason, no one has done more than attempt to log in so far, despite the simple password, so I have no log replays to show you right now. When I finally get a good one, I'll post it here so you can see how it works.
Tektip has some good videos on HoneyDrive and Kippo too. I recommend you watch them to get a greater feel for how all this works. I plan to try out some of the other honeypots in Honeydrive soon, but I'm currently enjoying working with Kippo. I'll probably try out Honeyd in the next couple days, however.
If you've always been curious about running a honeypot, I can't recommend HoneyDrive strongly enough. It is, without a doubt, the fastest and easiest way to get started. Congratulations and thanks to Ion for putting it all together. Thanks also to all the honeypot and other tool developers whose work is included in HoneyDrive.
Subscribe to:
Posts (Atom)